Windows Server 2012 Registered I/O Performance - take 2...
I’ve been looking at the Windows 8 Registered I/O Networking Extensions since October when they first made an appearance as part of the Windows 8 Developer Preview. Whilst exploring and understanding the new API I spent some time putting together some simple UDP servers using the various notification styles that RIO provides. I then put together some equally simple UDP servers using the “traditional” APIs so that I could compare performance.
I had my first attempt at performance comparisons back in March and whilst the results were in RIO’s favour they weren’t especially compelling given the new API you needed to learn and the fact that the resulting code would only run on Windows 8/Server 2012 and later. As I moved on from the simplest servers to more complex ones it became increasingly difficult to justify the code change for the performance improvement. I began to doubt my test environment and so upgraded the networking from teamed 1Gb connections to a pair of Intel 10 Gigabit AT2 cards wired back to back. It then became apparent that whilst my test server was fine in this configuration, I didn’t have another machine that was powerful enough to do the networking justice… After adding another new machine to the test system I could finally drive the 10 Gigabit AT2 cards at full capacity and having just begun to run the original tests again I can now clearly see the advantage of using RIO.
Do bear in mind that I’m learning as I go here, RIO is a new API and there is precious little in the way of documentation about how and why to use the API. Comments and suggestions are more than welcome, feel free to put me straight if I’ve made some mistakes, and submit code to help make these examples better.
Our test system
Our test system consists of a dual Xeon E5620 @ 2.40GHz (16 cores in 2 Numa nodes with 16GB of memory, running Windows Server 2012 RC) and an Intel Core i7-3930K @ 3.20GHz (12 cores with 32GB of memory, running Windows 7). These are connected by a pair of 2 Intel 10 Gigabit AT2 cards wired back to back.
How to test RIO’s performance
The test results presented here are from running the same tests that we ran back in March on the new hardware.
How the results differ with the new hardware
Back in March, sending 10,000,000 datagrams took a little over a minute and both the traditional polled UDP server and the simple RIO server performed about the same; datagrams being transferred at a rate of around 114,000 per second by both programs. We had to ramp up the “work load” on the servers to see any real differences, burning CPU for “datagram processing” to steal it away from dealing with the networking APIs. Running the tests again, with no “work load” gives us 10,000,000 datagrams in 59,934ms, with 7,346,468 datagrams received at a rate of 122,000 datagrams per second for the traditional server design. The simplest RIO server performs much better; completing the test in 20,736ms, with 9,999,982 datagrams received at a rate of 482,000 datagrams per second.
Digging deeper into RIO’s performance
This time around it’s fairly obvious that using RIO is worth the effort when using these simple server designs and digging into the perfmon logs for the test shows us that, as with our previous tests, the traditional UDP server spends most of its time in kernel mode (the thick blue line in the graph below).
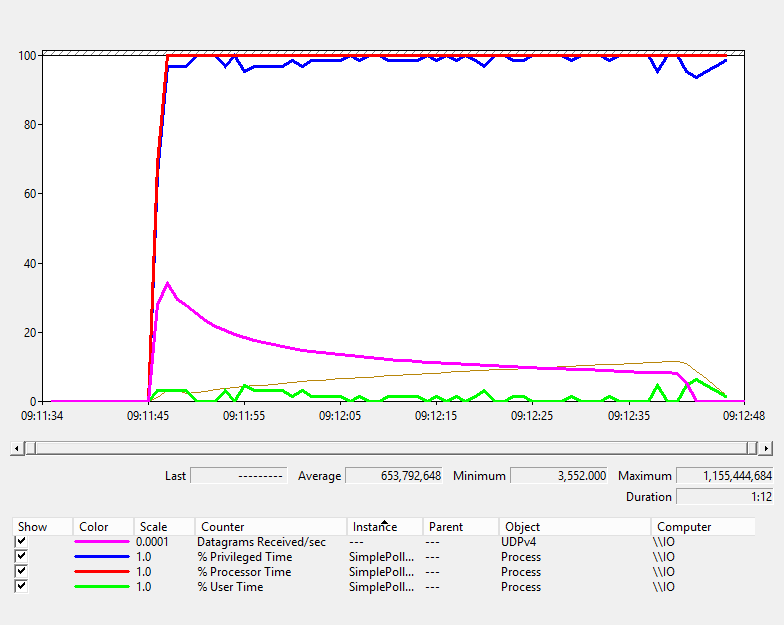
RIO Perf - Simple Polled UDP
Whilst the RIO server spends most of its time in user mode (the dotted green line at the top of the screen in the graph below).
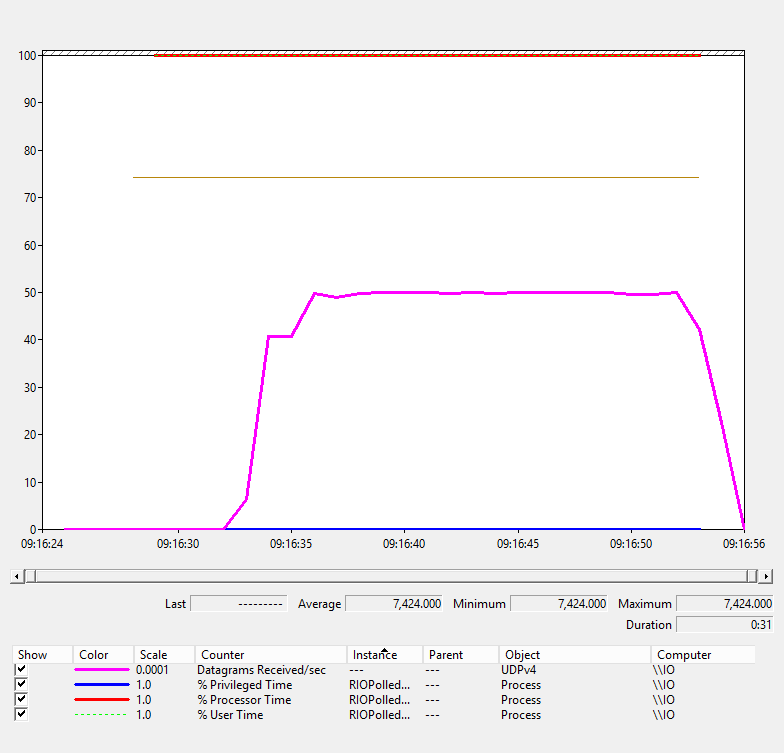
RIO Perf - RIO Polled UDP
Something else to note is the pink line. This is the number of datagrams received per second. On the traditional UDP server the server is quickly overwhelmed and the number of datagrams received slows. The RIO server suffers no such problem and maintains a steady flow of datagrams.
As before, non paged pool usage for RIO is lower and stable whereas it’s unpredictable and much higher in the traditional server design.
Using a 10 Gigabit link and machines which can fully utilise that link shows how effective RIO can be. Now that we have a reasonable baseline we’ll continue these experiments with the more advanced IOCP based RIO server designs.
If you’re interested in digging deeper into the results used in this article then all of the performance logs taken whilst running the tests are available here.
Code is here
Full source can be found here on GitHub.
This isn’t production code, error handling is simply “panic and run away”.
This code is licensed with the MIT license.