Windows 8 Registered I/O Performance
I’ve been looking at the Windows 8 Registered I/O Networking Extensions since October when they first made an appearance as part of the Windows 8 Developer Preview. Whilst exploring and understanding the new API I spent some time putting together some simple UDP servers using the various notification styles that RIO provides. I then put together some equally simple UDP servers using the “traditional” APIs so that I could compare performance.
Of course these comparisons should be taken as preliminary since we’re working with a beta version of the operating system. However, though I wouldn’t put much weight in the exact numbers until we have a non-beta OS to test on, it’s useful to see how things are coming along and familiarise ourselves with the designs that might be required to take advantage of RIO once it ships. The main thing to take away from these discussions on RIO’s performance are the example server designs, the testing methods and a general understanding of why RIO performs better than the traditional Windows networking APIs. With this you can run your own tests, build your own servers and get value from using RIO where appropriate.
Do bear in mind that I’m learning as I go here, RIO is a new API and there is precious little in the way of documentation about how and why to use the API. Comments and suggestions are more than welcome, feel free to put me straight if I’ve made some mistakes, and submit code to help make these examples better.
Please note: the results of using RIO with a 10 Gigabit Ethernet link are considerably more impressive than those shown in this article - please see here for how we ran these tests again with improved hardware.
How to test RIO’s performance
The tests consist of sending a large number of datagrams to the server under test. We send two sizes of datagram, the test datagram and the shutdown datagram. The server counts the datagrams that it receives and the time taken. It shuts down as soon as it receives a shutdown datagram. The servers that we are using for these tests are detailed here and the datagram generator is available here.
Whilst the numbers that the servers report are useful for getting a rough idea of how the various API’s compare they’re not the whole story. It’s useful to look at performance counter logs that are taken whilst the test server is running. The CPU usage of the server under test, and the entire machine, are useful indicators of how much further we could push a given server. The number of datagrams received, and dropped by the network and Winsock are useful to see, as is the non-paged pool usage, etc.
To make the testing repeatable I’ve put together some simple scripts which create the required performance logs using logman, the command line interface to perfmon. This means that for each test run we can run a single command which creates and starts a performance counter log, runs the server and then stops the performance counter log. It would be nice to include custom performance counters in each of the example servers so that we can see more of what’s going on inside, but whilst easy to do, using our Performance Counters Option pack, that’s beyond the scope of these tests.
The test client, or clients for when we’re using two network links into the test machine, are started manually. We could automate this with winrs, as we’ve done in the past, but these tests don’t really warrant that level of complexity.
Our test system
Our test system consists of a dual Xeon E5620 @ 2.40GHz, that’s 16 CPUs in 2 Numa nodes with 16GB of memory. The machine has four 1Gb Ethernet network intefaces, a Broadcom BCM571C NetXtreme II GigE with two channels and a Intel 82576 Gigabit dual port adapter. We’re using the Intel adapter for all of the tests shown here, sometimes using one NIC and sometimes two.
Windows Server 8 beta Datacentre edition is running directly on the hardware.
The client hardware is less impressive, but both client machines can push their 1Gb network interfaces to around 98% whilst running our datagram generator and that’s more than enough for our purposes here.
The first tests
To get a feel for how the RIO API differs from the traditional API’s the first test will compare a polled RIO server with a traditional, blocking, polled server. The code for the servers is available here along with some commentary on their designs. You’ll need Visual Studio 11 to build the examples.
The test scripts, mentioned above, can be downloaded from here. Each server has its own script and a text file that details the performance counters to capture during the test run. All of the scripts call a common script which sets up the performance counter log and then starts the server. You shouldn’t start the clients until the server is running and has output its configuration details. Once the server receives its first datagram it will display “TimingStarted” and when it has received a shutdown datagram it will display “TimingStopped” and display the number of datagrams that it managed to receive, the time taken and the datagrams per second. You need to copy the x64 release builds of the example servers into the same directory of the test scripts and then be sure to run the batch file and not the exe directly.
As an initial test we will run the traditional UDP server with one test client. We’ll set the test client to send 10,000,000 datagrams, which takes a little over one minute. Once the test was completed the server reported that it had processed 9,952,510 datagrams in 86,880ms, a rate of 114,000 per second. Running the RIO polled server example with the same network load the results were broadly similar; 9,932,228 datagrams in 86,681ms, a rate of 114,000 per second.
At first glance it seems that RIO isn’t so impressive, however we need to remind ourselves of what these example servers are doing; all they’re doing is pulling datagrams off of the wire as fast as they can. They’re both doing so on a single CPU of a 16 CPU machine and, from these results, it seems that on, this hardware, both APIs can quite easily handle a single saturated 1Gb network link.
Digging deeper into RIO’s performance
Whilst the two servers at first appear to behave almost identically under the load it’s only when we start looking at the performance counters that we can see that actually the two APIs have completely different performance characteristics.
Here’s the graph for the traditional UDP server. Note the thick blue line, that’s the amount of time the process spends in kernel mode, on average 37.133% of its time.
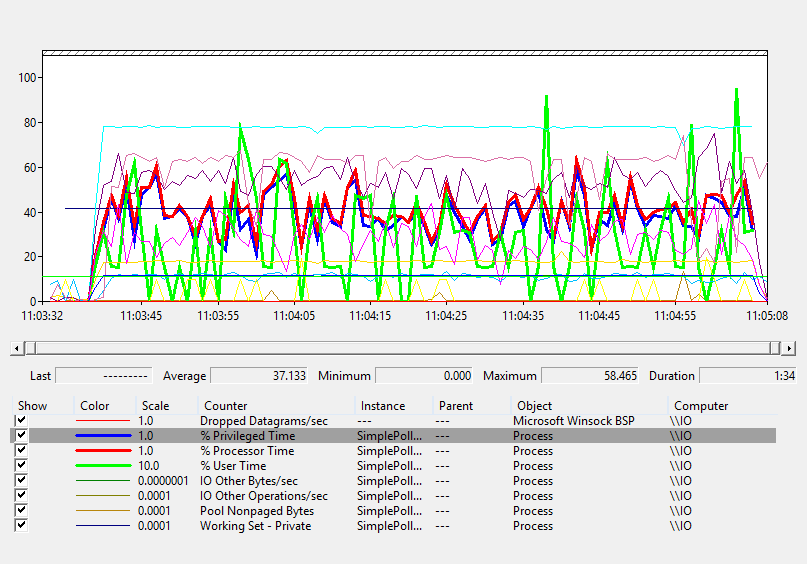
RIO Perf - Simple Polled UDP
this is likely still an advantage.
The RIO API isn’t especially complicated but your server designs will be different. The simple polling example server that we used here is unlikely to be an ideal choice as it uses 100% of its CPU for the whole time that the server is running. It’s also a little unfair to compare RIO to such a simple traditional server but; there are better alternatives, but it’s a useful line in the sand. As we’ll see in the following performance articles there are better, and more scalable ways to use both APIs.
If you’re interested in digging deeper into the results used in this article then all of the performance logs taken whilst running the tests are available here.
Code is here
Full source can be found here on GitHub.
This isn’t production code, error handling is simply “panic and run away”.
This code is licensed with the MIT license.