Windows 8 Registered I/O Buffer Strategies
One of the things that allows the Windows 8 Registered I/O Networking Extensions, RIO, to perform better than normal Winsock calls is the fact that the memory used for I/O operations is pre-registered with the API. This allows RIO to do all the necessary checks that the buffer memory is valid, etc. once, and then lock the buffer in memory until you de-register it. Compare this to normal Winsock networking where the memory needs to be checked and locked on each operation and already we have a whole load of work that simply isn’t required for each I/O operation. As always, take a look at this video from Microsoft’s BUILD conference for more in-depth details.
RIO buffers need to be registered before use
The recommended way to use RIORegisterBuffer() is to register large buffers and then use smaller slices from these buffers in your I/O calls, rather than registering each individual I/O buffer separately. This reduces the book-keeping costs as each registered buffer requires some memory to track its registration. It’s also sensible to use page aligned memory for buffers that you register with RIORegisterBuffer() as the locking granularity of the operating system is page level so if you use a buffer that is not aligned on a page boundary you will lock the entire page that it occupies. This is especially important given that there’s a limit to the number of I/O pages that can be locked at one time and I would imagine that buffers registered with RIORegisterBuffer() count against this limit.
Here we can see some common problems when you fail to take the locking granularity of the system into consideration when registering I/O buffers for RIO.

RIO - Buffer Alignment
To avoid locking more memory than you need to always align your buffers by allocating with VirtualAlloc(), or VirtualAllocExNuma(). Note that these both work in terms of pages of memory though the allocation size is specified in bytes, also note the alignment restrictions; the start of each allocated block will be on a boundary determined by the operating system’s allocation granularity (see here for why). You can obtain both page size and allocation granularity from a call to GetSystemInfo().
So, to allocate buffers for RIO efficiently you should use VirtualAlloc() to ensure alignment and you should allocate blocks which are multiples of the operating system’s allocation granularity (or you’ll be leaving unusable holes in your memory area). Some code like this might work:
SYSTEM_INFO systemInfo;
GetSystemInfo(&systemInfo);
const DWORD gran = systemInfo.dwAllocationGranularity;
const DWORD bufferSize = RoundUp(requestedSize, gran);
char *pBuffer = reinterpret_cast<char *>(VirtualAlloc(
0,
bufferSize,
MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE));
if (pBuffer)
{
RIO_BUFFERID id = rio.RIORegisterBuffer(pBuffer, bufferSize);
if (id == RIO_INVALID_BUFFERID)
{
// handle error
}
}
Buffer slices
Once you’ve registered your buffer you then access it using RIO_BUFs. The RIO_BUF is a handle to a “slice” of a RIO buffer and is very similar to the familiar WSABUF that’s used in normal Winsock calls. It’s simply a buffer id, a start offset and a length. You might decide that you’ll allocate one block of memory for your I/O buffers and that would be 64K in size (since 64K is the allocation granularity on x64 and x86) and then perform I/O in terms of fixed sized buffers of 4096 bytes, or whatever. You could then have a series of RIO_BUFs, the first points to offset 0 and has a length of 4096, the second points to offset 4096, etc.
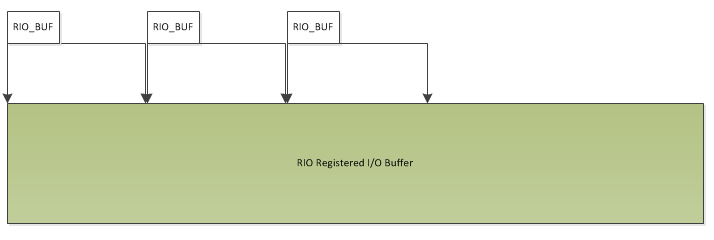
RIO - Buffer Slices
Alternatively you might write a memory allocator that sits over your RIO registered buffers and allocates portions on demand for whatever size you need, although personally I favour using fixed sized I/O buffers. Many server designs may have messages which are naturally limited in size and work fine with single fixed sized buffers for send and receive operations. When your data is larger than a single buffer you can chain buffers together. For sending you can then send the chain using scatter/gather I/O and for receiving you can simply fill a buffer, allocate another and chain the buffers together so that you can process complete messages. We’ve been using fixed sized buffers in The Server Framework for over 10 years and they work just fine in general purpose situations as long as you can select a buffer size that makes sense for most operations. The one potential reason to want to use dynamic buffers for RIO is that whilst the header’s show that RIOSend() supports scatter/gather I/O the documentation says that it doesn’t and the Microsoft BUILD video implies that the extra parameters are ‘reserved’. Even so, with RIO’s strict limits on the number of outstanding operations (and the number of buffers used with those operations) using our current “send a chain of buffers” style of design may not work so well with RIO. We’ll see. For now I’ll be sticking to fixed sized buffers as I don’t believe that placing a custom memory allocator over the top of the RIO buffer will perform well enough; it may well be that we end up with an allocator that can allocate a variety of fixed sizes from different pools…
An augmented RIO_BUF
The RIO_BUF is too simple a structure to manage complex buffering requirements. Since we’ll likely be using I/O completion port based completion handling in our RIO code we’ll need a way to manage the lifetime of the buffer slices that we’re using. For example, the slice is active from the moment we allocate it to put outbound data into it, until the write completion occurs, at which time it could be returned to the allocator, or, reused directly. I’ve found that reference counting works well for this, it also allows for flexible server designs as, when reading, you can easily manage the extended lifetime of a buffer that you need to place in a chain, or pass off to another thread for processing. You can see the OVERLAPPED based buffer interface that we use for IOCP servers in The Server Framework here, I imagine that the RIO buffer interface that I come up with will be similar, but somewhat simpler and without the OVERLAPPED. So, we now have a RIO buffer slice that’s managed by a separately allocated ‘buffer’ object. You can see an example of this management object in the code for our example servers, here.
Buffer slice management
Since our buffer allocator will provide fixed sized buffers and work in terms of large blocks of memory for registering with RIO. It’s probably also worth allocating a single large block of memory for all of the corresponding buffer objects that will manage the slices. We would then use placement new to allocate each of the objects in the single large block. We’d end up with two blocks of memory, like this:
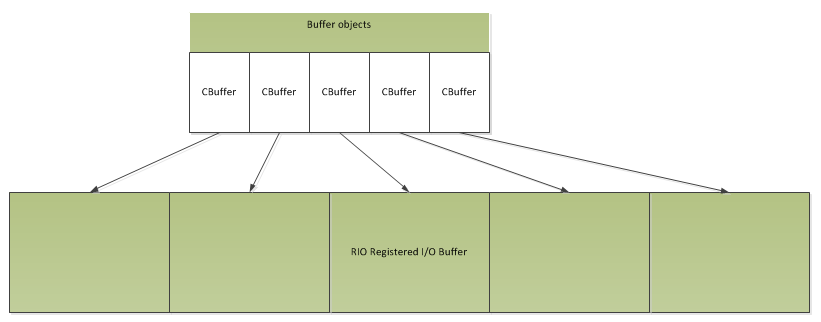
RIO - Buffers
The first would contain all of the buffer objects that manage the reference counts on the slices, hold the RIO_BUF structures and contain any book-keeping data we might need, the second be registered with RIO and locked in memory. The allocator would then allocate new blocks of memory as it needs them and, if the buffer objects also manage a reference count on the allocator’s data blocks, it could de-register and release buffers when they’re no longer in use (as long as it’s pooling enough buffers for later use…).
One thing to bear in mind here is that my design here is naturally driven towards being flexible and general purpose. The reason for this is that’s the way The Server Framework works; yes it’s always possible to get better performance from code that’s designed specifically for one single server, but with our framework you can get a working server up and running very quickly and, in most situations, you’ll find that you don’t need to tune the code much at all for your specific server. Also I find that it’s easier to get started this way…
As an alternative to a buffer allocator which manages pools of RIO buffers we might, instead want to allocate buffers per connection. After all, RIO limits the number of operations that can be pending at one time on a connection, so we could, in some situations, know exactly how many buffers we might need and assign them to the connection when it’s established. Whilst this may perform better in some situations, per socket buffer pooling is something that can be added on top of a pooling buffer allocator (and this is currently being investigated in The Server Framework anyway), so we’ll look at it later if necessary.
So, that’s the idea… More on this when I have some code.
Code is here
Full source can be found here on GitHub.
This isn’t production code, error handling is simply “panic and run away”.
This code is licensed with the MIT license.